Five times a second, someone edits Wikipedia. Seventeen times a second, someone posts to Bluesky. Add Reddit and Hacker News and that’s tens of thousands of people an hour, each acting on their own, with little idea their actions are part of a bigger picture. Somewhere in the activity of all those people online is information converging and possibly breaking before it’s been made official. That is, if you can read it fast enough. And then the catch is that fast and true are different problems, and the hard part isn’t reading the stream, it’s knowing when to believe it. For a few months I’ve been pointing AI narrators at live data streams to see what surfaces, and how different streams answer that question of trust.
This started with my Wikipedia experiment; since then I’ve run two more on other streams, with wildly varying results. Here’s a recap of what I’ve found so far.
A curated stream makes for a confident narrator
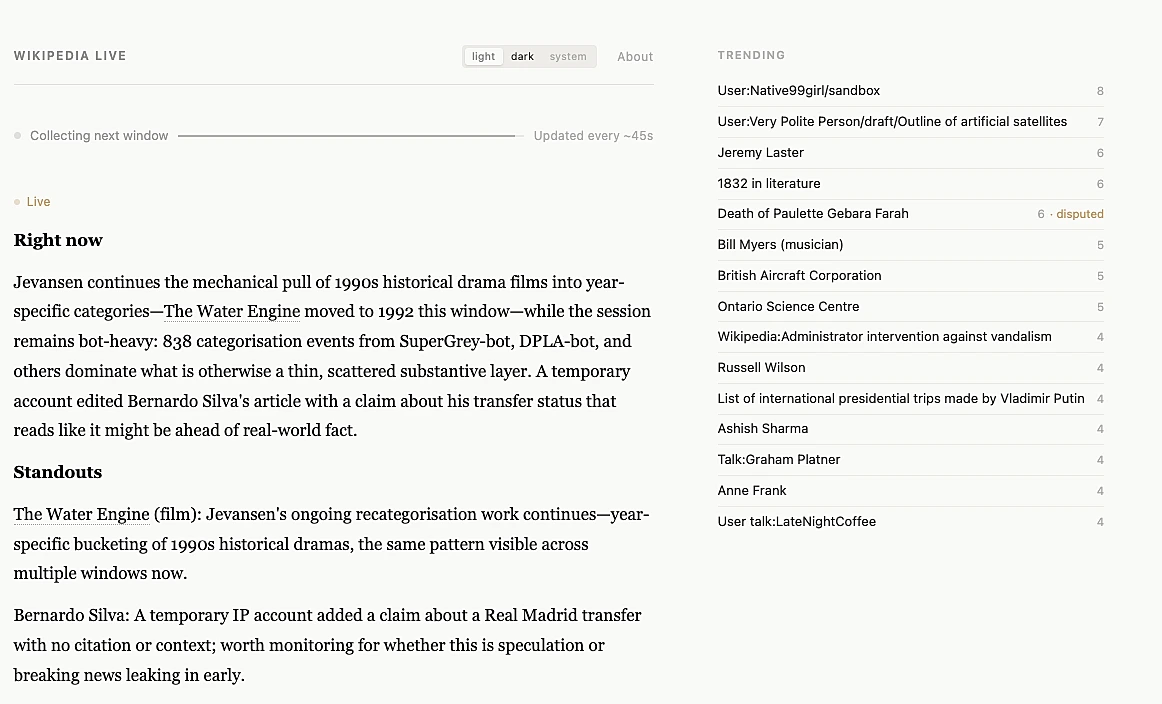
The question I started with was, what would it look like for a high-volume data stream to be read in plain language? Wikipedia was a great testing ground: the edits never stop, far faster than anyone could follow, and most of that activity is invisible in page titles, usernames, and edit summaries streaming past in a raw firehose that’s fascinating in theory and unreadable in practice.
wikipedia.datastories.live connects to Wikimedia’s public edit stream, filters it down to substantive human edits on English Wikipedia, and feeds rolling 60-second windows to Claude. The model watches each window and writes a short narrative: what’s being edited, who’s editing, what patterns are emerging, and what that might say about what the world is paying attention to right now.
What the app surfaces most clearly is the hum of human attention. Someone correcting a stray bracket in a plant taxonomy article. A dispute over whether haggis is uniquely Scottish. The NFL draft arriving in the edits in real time. And the model isn’t summarising this so much as interpreting it. Given the same window of events, it can tell a pattern from noise, flag when something is unusual compared to the session average, and notice when the same article keeps reappearing. That’s closer to what a person would do, if a person could read all of it (they can’t). Almost nothing here is at stake, since a misread edit is reverted in seconds.
What I didn’t appreciate at the time was how much the stream itself was doing for me. Wikipedia comes pre-edited, even when it doesn’t feel that way. Every edit is reversible. Bots are tagged. Vandalism is reverted, usually within seconds. The community has spent two decades quietly building a quality layer around the firehose, and by the time an event arrives at the SSE endpoint the structure is already there: bot or human, edit or new page, article or talk page, reverted or not. I could filter on any of that with a single field. The narrator’s job, in that environment, was to pay attention and write something small and true. It never had to wonder whether the events it was reading were real.
A raw stream forces the narrator to stop asserting
The second app watches Bluesky through the AT Protocol Jetstream, a public firehose of every post created on the network. Compared to Wikipedia’s 5 edits per second, Bluesky has around 17 original posts per second, once you filter out replies. There is no revert, no bot tag, no consensus mechanism. Rumour, satire, grief, sports results, and outright fabrication arrive with identical weight.
That changes the narrator’s job. The Wikipedia app could say “this article is under sustained editing” and be right. On Bluesky, the honest equivalent of any claim is “posts are reporting that X happened,” because that’s the most the stream can tell you. A claim spreading across thirty accounts is not corroboration. It might be coordinated. It might be a misread that went viral. It might be true.
The first version of the app didn’t understand this, because I hadn’t told it to. During testing it reported that Kyle Busch, the NASCAR driver, had died at 41. Five windows (around 5 minutes) later it reported his hospitalisation. Both came from user posts and both were stated as fact. Neither was necessarily true (Busch is alive), and the app had no way to know that. The narrator was doing exactly what it was instructed to do, read the window and write a confident narrative, and the instructions assumed a level of verification the stream couldn’t provide.
The narrow fix was a rule placed in the prompt before everything else:
Bluesky posts are written by anyone. They contain rumours, jokes, misreadings, satire, and outright errors as readily as facts. Never assert the content of a post as a fact about the world. When posts describe events (deaths, disasters, breaking news, public-figure incidents) describe what people are saying, not what happened.
Another thing to note, was that where Wikipedia could build a story out of 60 seconds worth of edits, Bluesky’s stream doesn’t easily resolve into a story. A 60-second window might contain a Roland Garros fine claim with a single source, Iran releasing footage of Revolutionary Guards, a parent writing about loving their kid extra hard because it’s Pride, and someone’s pet snail dying mid-Pokémon playthrough. Taken together, these don’t add up to anything, they’re just what was happening at 11:53 on a Monday. The prose format kept trying to smooth that into coherence, which made it dishonest. The window isn’t a story, it’s a cross-section.
So the redesign was: stop narrating, start observing. The narrator’s job shifted from writer to witness. The app now produces short observations (“Roland Garros $65k fine claim circulating, single source cited”) and a set of post fragments for an ambient strip that cycles on screen. The fragments aren’t a highlight reel. They’re a sample. Here are three posts from the same 60-second window:
when I went INTO the Outback Steakhouse, my ass wasn’t sticky
Iran releases footage of Revolutionary Guards patrolling the Strait of Hormuz
They got this suit. For him. Just so he can be buried with it.
Two other problems showed up that Wikipedia never posed:
First, coordinated spam can be semantically coherent in a way Wikipedia vandalism usually isn’t. The vandalism that reaches the stream mostly looks like vandalism, implausible edits that bots revert in seconds. During testing, a hashtag campaign slipped through my filters because the posts were varied enough, long enough, and spread across enough accounts to read as organic. The narrator, though, spotted the coordination within the first window and tracked it across the next four. Then it kept leading with it, because it was the most consistent pattern in the data. The current rule: name the campaign on first mention, treat it as background afterwards, find the organic content underneath.
Second, the slow signal. A single Pride Month post in a window is background noise. Pride Month across seven consecutive windows, with the register shifting each time from declarative to intimate to sardonic, is a pattern worth noting. The app has a separate step that reads across recent windows and names what’s genuinely recurring. If nothing is building, it stays silent, and most windows don’t build into anything. That silence turned out to be part of the data too.
Multiple streams start looking for convergence
My third experiment was an attempt at live reading on the tech news cycle. It polls Hacker News and a few subreddits every ten minutes, tracks which stories are gaining velocity, and asks Claude to write a short briefing. Of the three, this is the most unfinished.
The interesting design problem turned out not to be “narrate this window.” It was: what does two streams give you that one doesn’t? The answer I’ve arrived at, for now, is convergence. A topic rising in one community could be an artefact of that community. The same topic rising independently in two communities that don’t fully share an audience is closer to evidence. It’s a structural read on what the technical internet has decided is worth its attention right now.
Divergence is sometimes part of the story, too. The most useful output from one session flagged that r/technology was flooded with AI-and-corporate-accountability stories (the strongest gaining 275 points in ten minutes: a claim that twin brothers had wiped 96 government databases after being fired) while Hacker News sat nearly silent on all of it.
Specific enough to read and honest enough to trust
Each app is trying to do one thing: read a stream in real time and surface what seems to be happening, what’s unusual, what might be breaking, the way a skilled analyst would if anyone could read all of it at once.
Each stream ended up answering that question of trust differently. Wikipedia’s narrator can be confident because the stream is curated before it arrives. Bluesky’s narrator has to carry the epistemic weight itself, and that changes the voice: it can’t assert, only describe what’s circulating, and that turns out to be a more honest relationship with a raw stream than narrating it like news. Tech news isn’t one stream to narrate at all; it’s two streams being compared, which is a different verb.
Under all three sits the same tension, between accurate and useful. A narrator that says “the communities are split” every window is accurate and useless. A narrator that says “Kyle Busch has died” when all it saw was posts is useful-sounding and unreliable. The work, as far as I can tell, is finding constraints that keep the output specific enough to be worth reading and honest enough to be trusted, and those constraints look different on every stream.
What’s next for these experiments
All three experiments are running. None are finished and they’re rough enough that I’d rather call them experiments than anything truly production worthy. The Wikipedia one is at wikipedia.datastories.live, the Bluesky one is at bluesky.datastories.live and the tech briefing (dicey) is at tech.datastories.live. They likely have bugs and directions I’m not sure about.
There’s something very interesting in the convergence angle, bringing multiple sources together to find and surface patterns. I’m looking into more data sources and next I’d like to bring multiple sources into a single app, to build on that convergence idea from the tech news app. I’d like to understand how journalists and social-monitoring people actually think about this, because I’m sure they will have hit the deeper version of every issue I’ve run into.
If you work with live data, news, or real-time signals, or you just look at one of these and have a reaction, I’d like to hear it. Some of the most useful course corrections so far have come from people who took five minutes and told me what they actually saw. To my mind, none of this should automate the real work of journalists, editors, analysts etc. It’s an interface for reading a stream at a glance, and I’m still following hunches and questions right now.
Try it out
If this resonates with you, connect and message me on LinkedIn